Speculative speculative decoding
논문 링크
개요
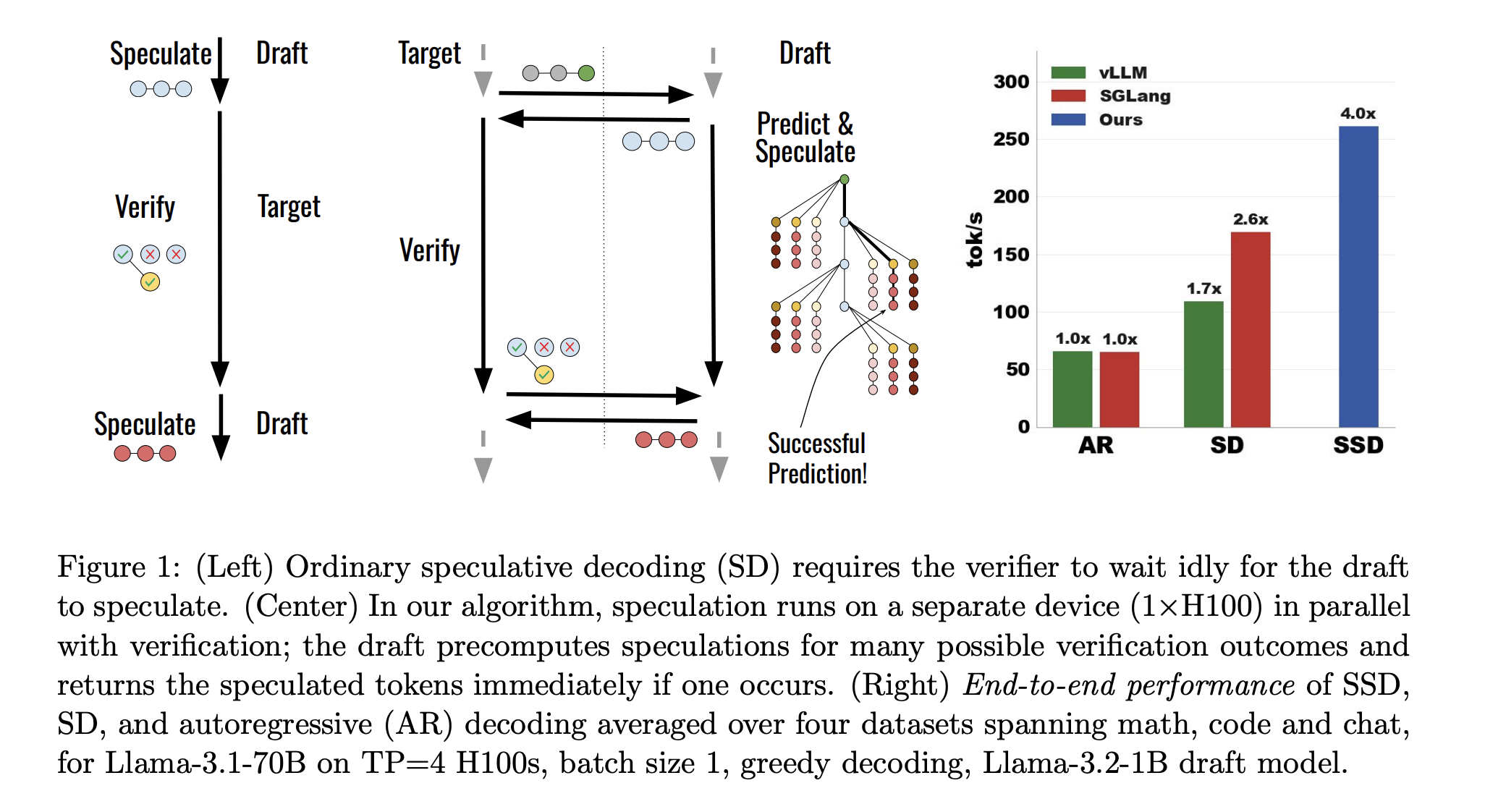
- Autoregressive 모델은 그 구조 자체가 sequential하기 때문에, inference가 느릴 수 밖에 없다. 이를 완화하기 위한 방식으로 speculative decoding이 사용되기도 한다.
- 하지만, speculative decoding 자체도 draft 생성 → 검증이라는 sequential한 스텝을 가지고 있으며, 이 때문에 완전한 병렬화는 되지 못한다.
- speculative speculative decoding는 target model이 draft를 검증하는 동안, 이 검증 결과를 예측한 뒤 draft를 추가로 만든다. 만약 검증을 통과한다면, 그대로 다시 검증 프로세스로 들어감으로써 overhead를 줄인다.
- 이를 하기 위해서 크게 세 가지 어려운 점이 있다.
- 검증 결과를 예측하는 것은, 얼마나 많은 토큰이 통과할지를 예측하는 것 뿐만 아니라, target model이 마지막에 생성하는 bonus token이 무엇인지도 같이 예측해야 한다.
- 실제 acceptance ratio를 올리는 것과, 검증을 잘 예측하는 것 사이에 미묘한 trade-off가 있다.
- 검증 예측이 실패했을 때의 fallback이 필요하다.
Speculative Speculative decoding framework
Algorithm

- verifier는 기존과 동일하게, spec_token을 받은 뒤 이를 병렬로 검증하고, 최종 bonus 토큰을 하나 생성하고 종료한다.
- speculator 역시 기존과 동일하게 draft를 생성한 뒤, verifier에게 보낸다.
- 이후, speculator는 얼마나 많은 토큰이 받아지며, 그 이후에 target이 생성할 토큰이 무엇인지 예측하고, 미리 그 이후 토큰 (cache)를 만들어둔다.
- 만약 이게 성공하면, 바로 캐시를 다시 verifier에게 전송
- 그게 아니라면, fallback을 수행한다.
Formulation
기존의 speculative decoding과 비교해서 speedup의 기대값은 아래와 같다.
\[speedup_{SSD} = \frac{p_{hit} \cdot E_{hit} + (1 - p_{hit}) \cdot E_{miss}}{p_{hit} \cdot max(1, T_p) + (1 - p_{hit}) \cdot (1 + T_b)}\]- p_hit은 캐시 hit 확률, E_hit, E_miss는 생성된 토큰 숫자에 대한 기대값으로, hit은 primary, miss는 backup (fallback) 이다.
- T_p, T_b는 각각 primary, backup speculator에서 걸리는 시간을 의미한다.
기존의 SD보다는 p_hit이 0보다 크다면 속도 향상이 반드시 있고, 그 크기는 아래와 같다.
\[(1 + T_{SD}) \cdot \frac{E_{hit}}{E_{SD}} \cdot p_{hit} \leq \frac{speedup_{SSD}}{speedup_{SD}} \leq (1 + T_{SD}) \cdot \frac{E_{hit}}{E_{SD}}\]
Saguaro: an optimized SSD algorithm
Cache construction
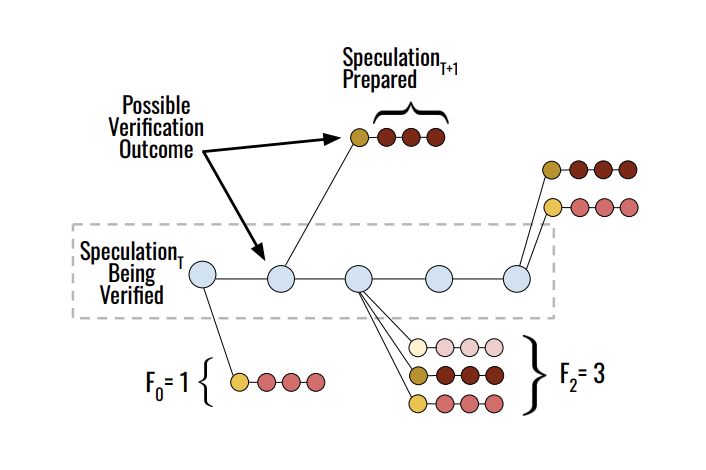
- Fanout을 사용. 즉, speculative sample이 거절될 경우를 대비해서 다음 토큰을 미리 tree 형태로 구성하는 전략이다.
- fanout의 크기는 이번 토큰에 대한 확신 (draft model의 probability), 그리고 깊이 (앞에서 reject이 발생하면 뒤쪽을 다 버려야 하므로)에 따라 결정된다.
Sampling
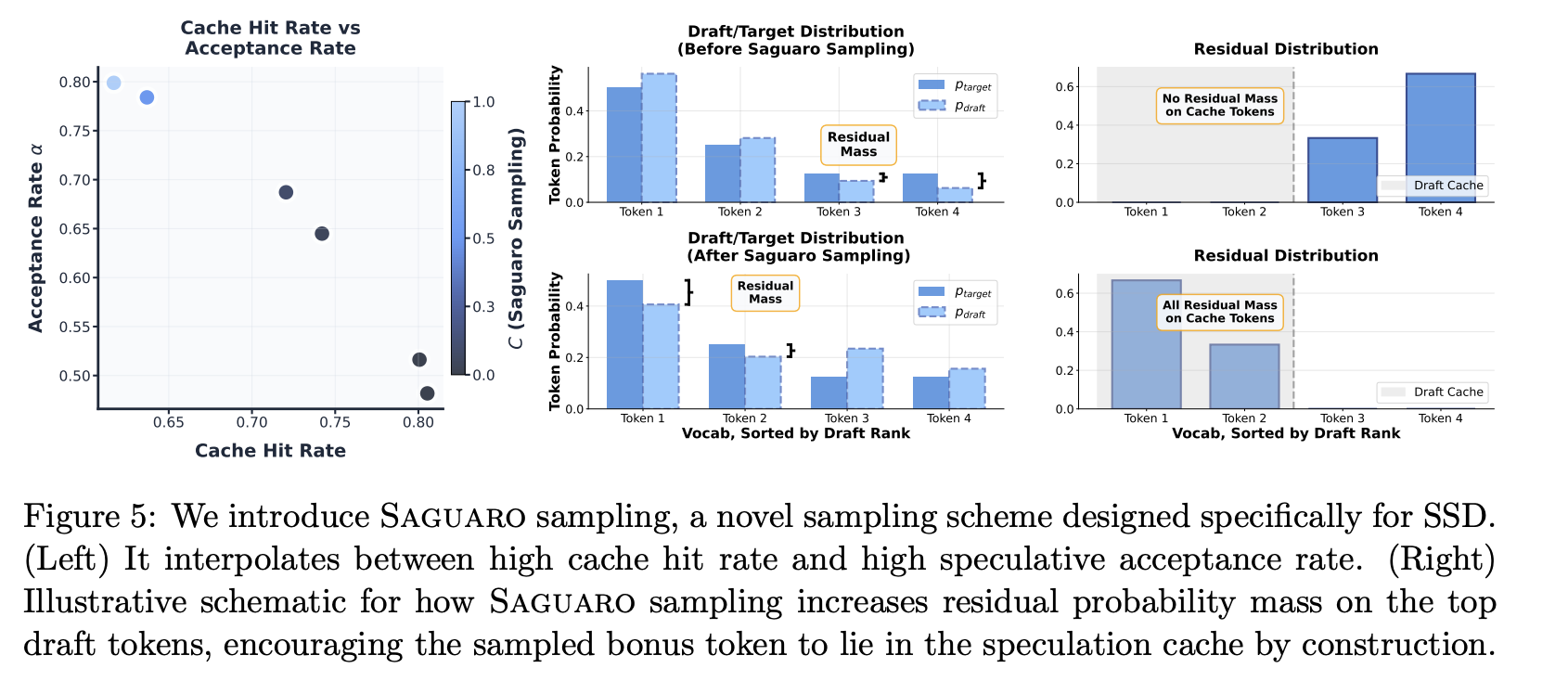
- 모든 토큰이 accept 되는 경우를 제외하면, bonus token은 residual distribution에서 나오는 경우가 많다. residual distribution은, 모든 토큰에 대해서 target의 확률에서 draft의 확률을 뺀 값이다 (최소 0으로 보장). 이 확률 분포는 temperature가 있는 환경에서 구하는 것이 어렵다.
- residual distribution과 유사하게 샘플링하는 방법은, draft distribution만큼의 확률 분포를 줄이는 것이다. 하지만, 이렇게 하면 target distribution과 멀어져서 오히려 acceptance ratio가 줄어드는 부작용이 발생한다.
- draft가 residual distribution과 유사하게 샘플링 (draft에서 높게 나온 토큰을 억제) 할수록, acceptance ratio는 줄어들지만 cache hit ratio는 올라감
- target은 draft가 무슨 짓을 하던 상관없이, 특정 토큰을 p의 확률로 샘플링 함. 기존 SD는 draft로 그걸 잘 맞추려고 했다면, SSD는 그 맞추는 확률을 draft / cache가 나눠먹는 구조. 그래서 tradeoff가 있음
- 따라서, 특정 hyperparmeter에 따라서 샘플링 방식을 결정한다.
Fallback
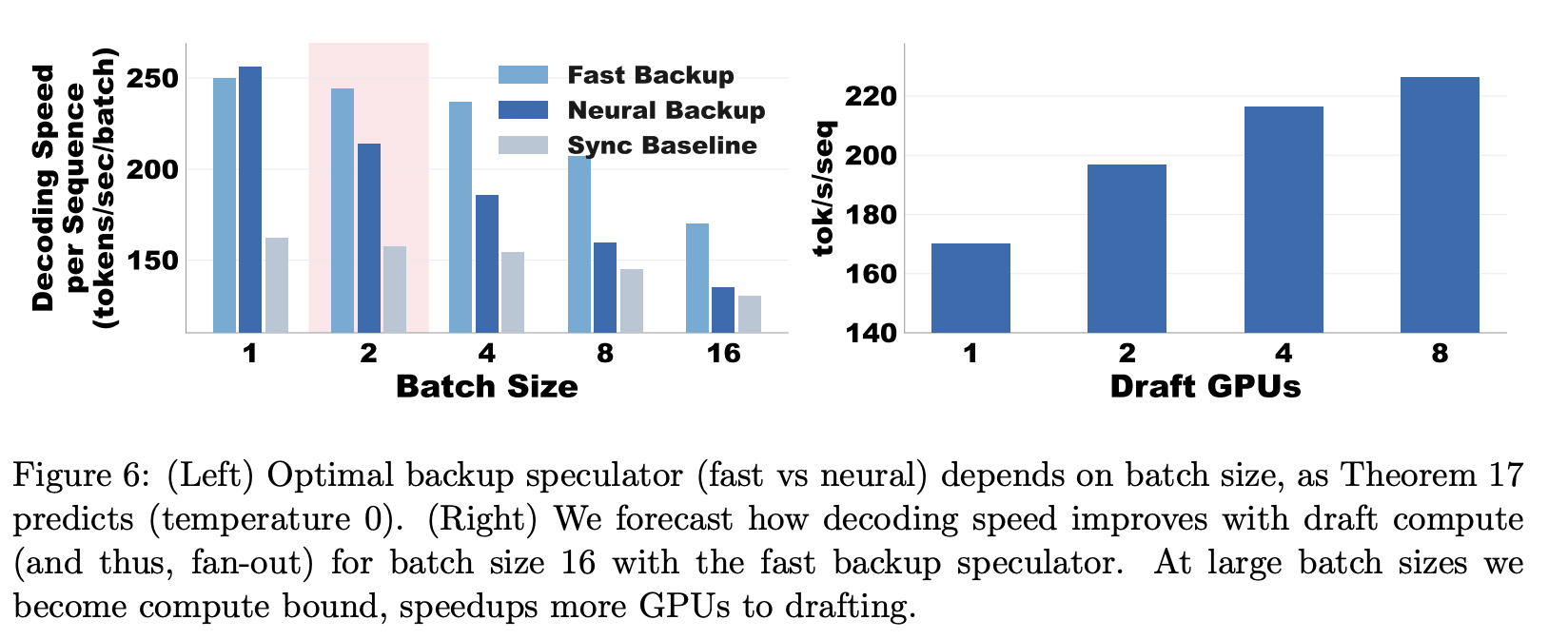
- 현상을 관찰해보니, cache miss는 대부분 large batch size에서 발생하고, 이로 인해서 큰 배치 전체가 backup을 기다리는 현상이 나타났다.
- 이를 완화하기 위해, batch가 작으면 backup과 primary를 동일하게, batch가 크면 더 빠르고 가벼운 speculator로 바꿔서 돌리도록 구성했다.
- 배치 사이즈가 커질수록, fast backup을 쓸 때 더 효과가 좋다.
실험
셋업
- target model은 H100 * 4 gpu 사용
- SD는 동일 하드웨어에 올라감
- SSD는 다른 H100 한 장을 추가해서 올림
- 모델
- llama 3
- qwen 3
- 데이터셋
- Alpaca
- GSM8k
- UltraFeedback
- HumanEval
결과
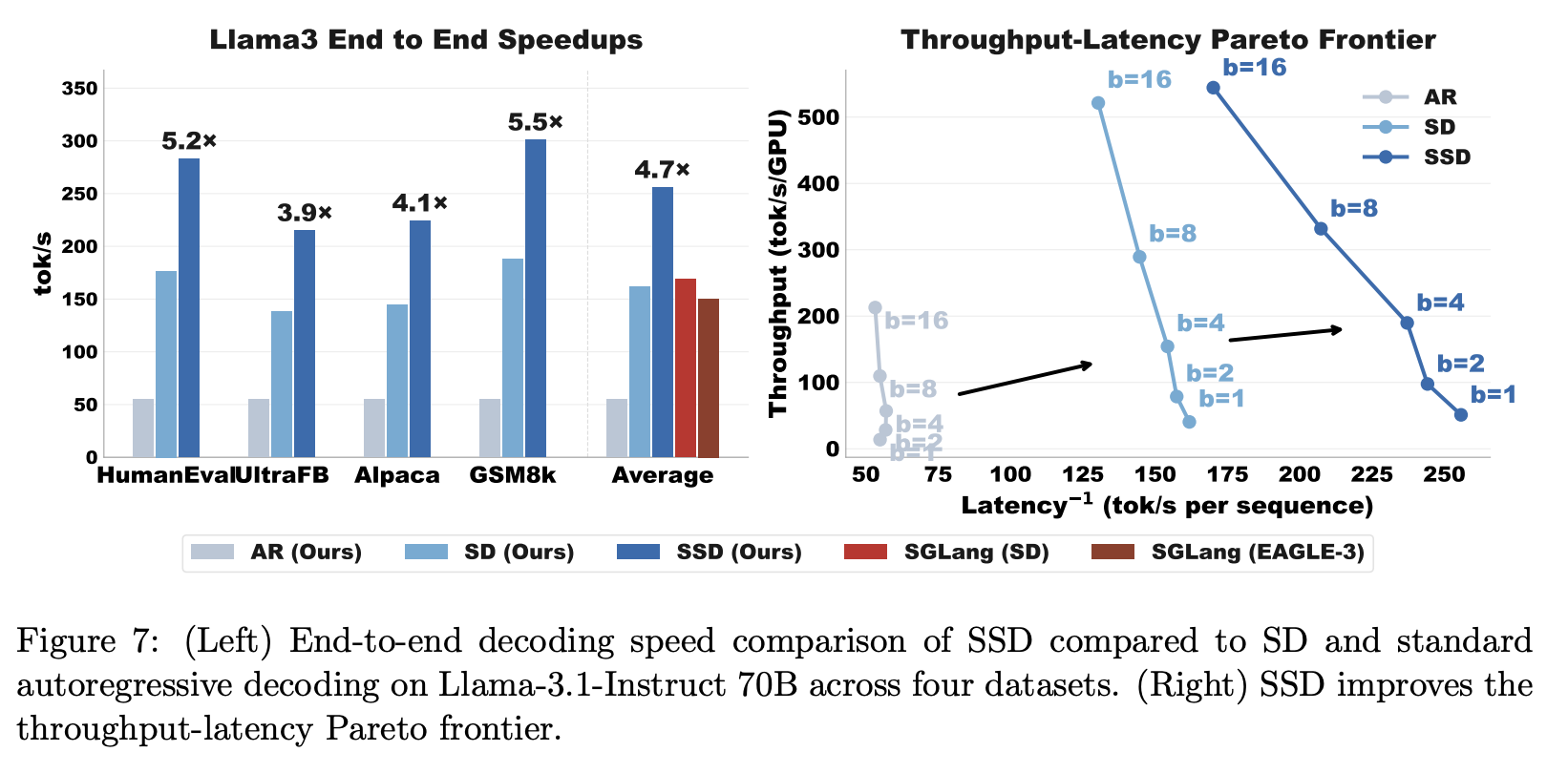
- speculative decoding을 어떤 방식으로 쓰던, ssd가 더 효과가 좋다.
- latency도, throughput도 더 좋음
결론
- SSD를 사용하면, SD의 throughput을 많이 올려주지 못하는 문제를 개선하고 더 빠르고 높은 처리량으로 토큰을 생성할 수 있다.
- EAGLE과 같은 형태에도 적용할 수 있는데, 이건 일단 future work.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.