Chain-of-verification Reduces Hallucination in Large Language Models
논문 링크
배경
- LLM은 hallucination을 생성하는 경향이 있다. 이를 해결하는 방법으로는 아래와 같은 방법들이 사용된다.
- 학습으로 해결하기 → RLHF, DPO 등의 추가 학습
- 추론할 때 해결하기 → DoLa 등 output distribution을 이용해서 수정
- 외부 데이터를 이용하기 → RAG, chain-of-though, 외부 툴 사용 등
- 하나의 LLM이 초안 생성과 fact check, 수정까지 모두 하도록 하고, 그 과정을 chain으로 엮음
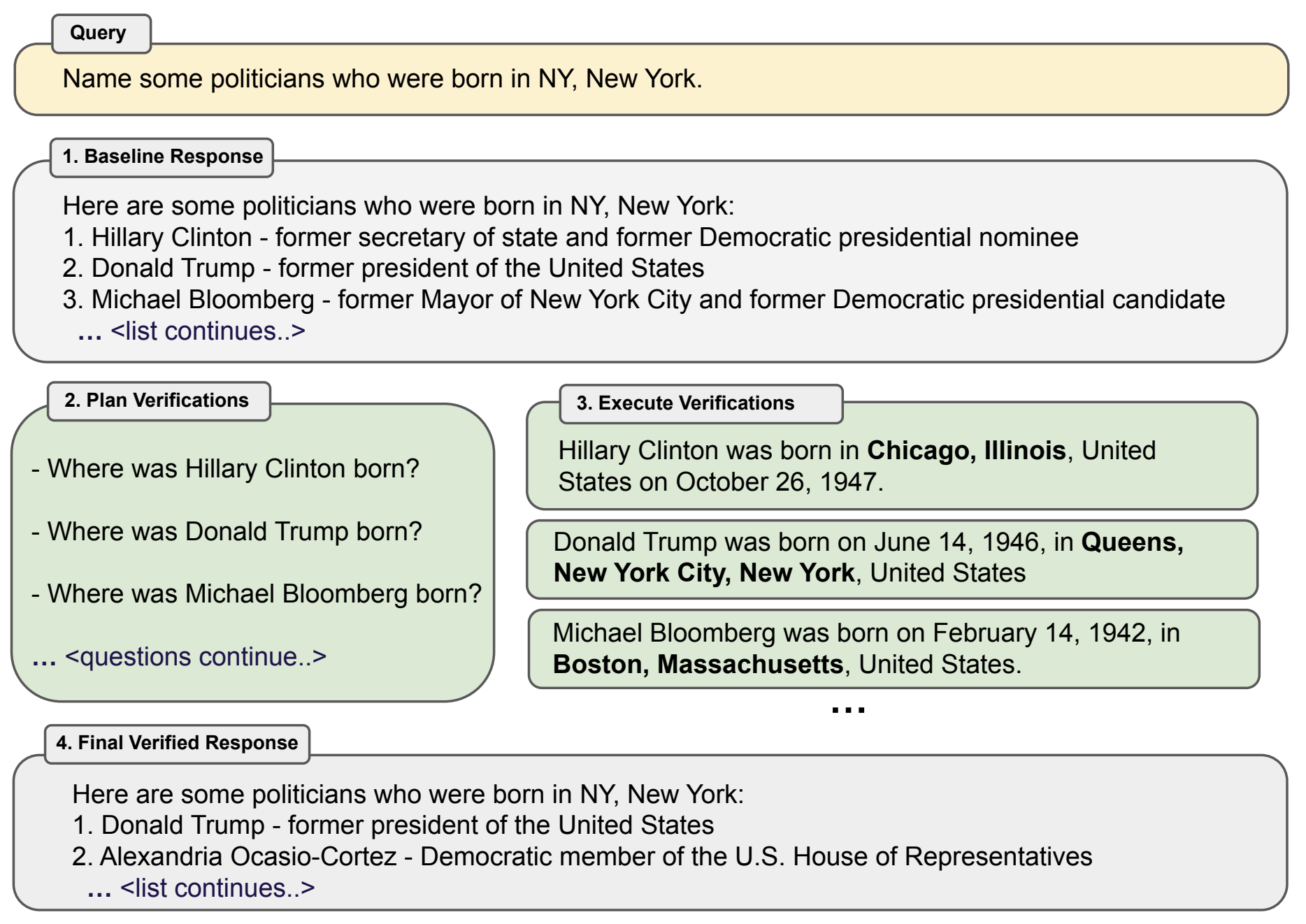
CoVe (Chain-of-Verification)
- 총 4단계로 구성됨
- 초안 생성
- 검증 플랜 (질문들) 생성
- 검증 답변 생성
- 최종 수정
- 초안 생성 단계
- 기존의 방법들과 다르지 않음. task에 따라서 few-shot을 생성하기도 함
- 검증 플랜 생성
- 질문과 답을 넣고, 답에 있는 사실과 그걸 검증하는 정답 페어를 생성하게 함.
- 아래처럼 few-shot을 넣어줬다고 함

- 이렇게 하는 instruct tuning을 거치고 나면, few shot이 아니고 zero shot으로도 가능할 것으로 보임
- 검증 실행
- 2단계에서 생성한 질문을 넣고, 답을 생성하도록 함.
- 총 4개의 방법을 테스트 해 봄
- Joint
- 한 번에 질문과 검증을 같이 하는 것. 즉, 생성한 답변에 대해서, 검증 질문과 관련 답변을 한 번에 생성하도록 함
- 이 경우, LLM이 생성한 첫 초안 답변에 영향을 받는다. 실제 prompt에 이 값이 들어갔으므로.
- 2-Step
- 두 단계로 나눠서, 질문 생성은 기존의 초안 답변대로 하도록 하고, 답변된 질문에 대해서 한 번에 답을 생성하도록 prompt를 구성
- Factored
- 여러 개 생성된 질문에 대해서, 하나씩 답변하도록 여러 차례 inference를 시킴
- 이러면 inference 시간이 늘어나는데, parallel하게 수행하도록 함
- Factor + Revise
- 원문과 factored 질문에 대한 답을 비교해서 cross-check하는 방법
- 여러 단계로 구성되는 것처럼 보임. prompt 예시

- Joint
- 최종 수정
- 앞에서 생성한 전체 데이터를 넣고 다시 생성하도록 함. few-shot을 사용했다고 한다

- 앞에서 생성한 전체 데이터를 넣고 다시 생성하도록 함. few-shot을 사용했다고 한다
실험
- Tasks
- WikiData
- wikidata API를 사용해서, list로 답변하는 퀴즈를 내는 방식. LLM은 wikidata에 비해서 훨씬 적은 수의 답변만 생성해서, precision만 metric으로 사용함
- 문제 예시:
Who are some politicians who were born in Boston? - 56개의 질문
- WikiCategoryList
- QUEST라는 논문에서 사용한 데이터를 사용. 어떤 카테고리를 주고 리스트로 답변을 생성하는 방식
- 문제 예시:
Name some Mexican animated horror films - 55개의 질문
- MultiSpanQA
- 추가적인 정보는 주지 않고, 그냥 질문만 입력함. 3개 토큰 이하로 생성이 필요한 질문 418개 선정
- 문제 예시:
Q: Who invented the first printing press and in what year? - 418개의 질문
- Biography (longform generation)
- 어떤 인물의 일대기를 요약하라고 하고, FactScore로 검증함
- WikiData
- Baseline
- PLM으로 Llama 65B, instruct tuned모델로 Llama2를 사용함
- 마지막 task에 대해서, chatgpt나 perplexityAI 등의 서비스도 같이 비교
- 실험 결과
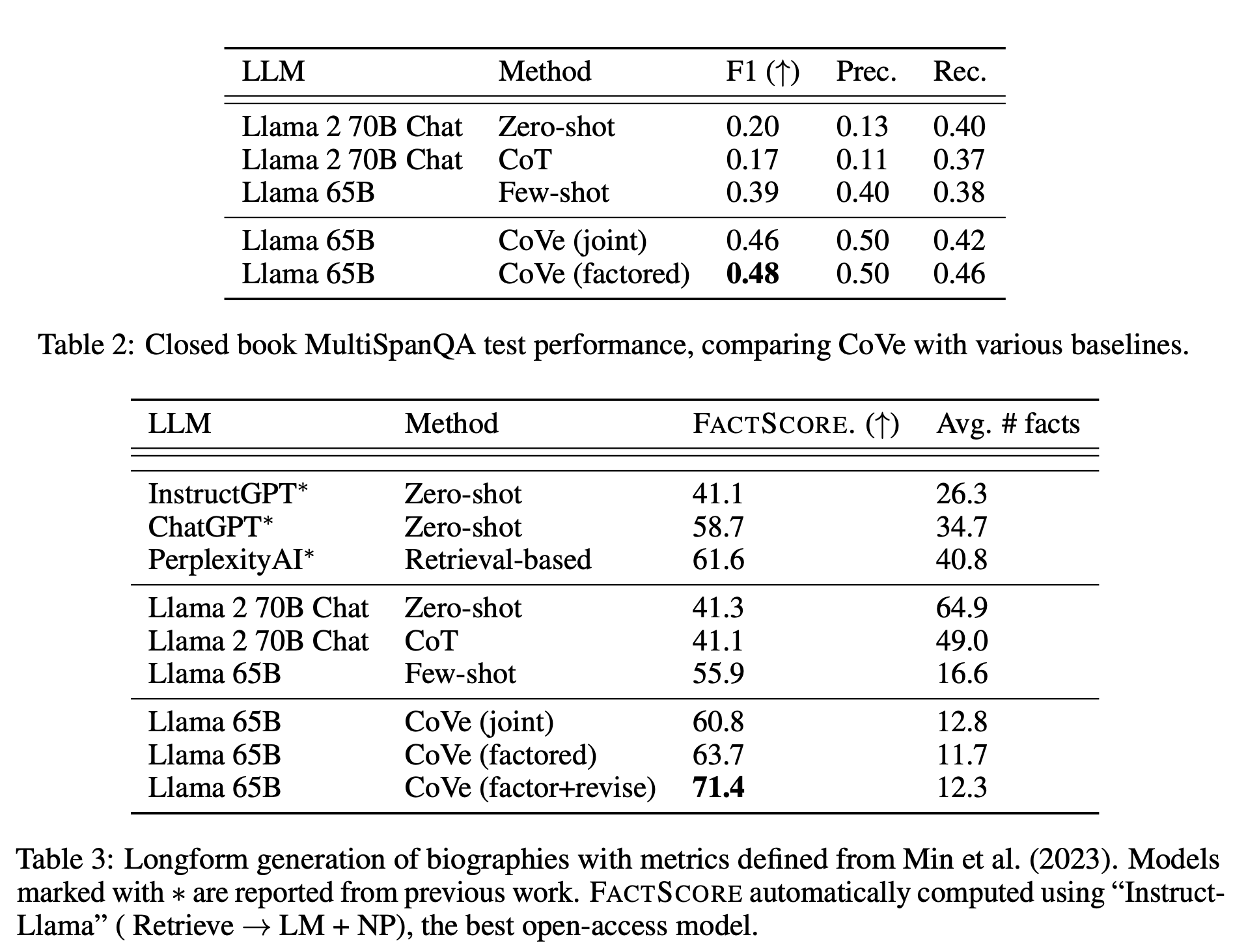
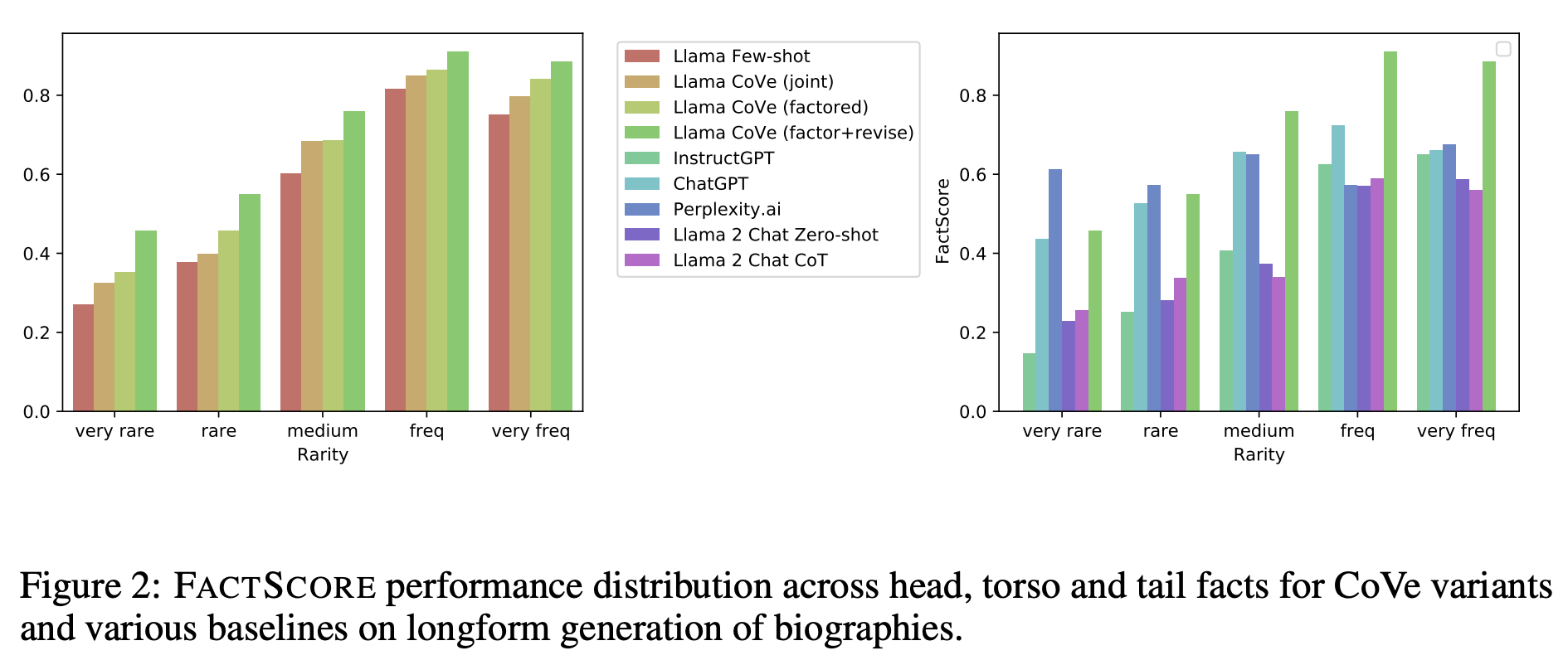
결론
- Lessons
- CoVe를 사용하면, 거의 모든 task에서 hallucination을 줄일 수 있다.
- Verification을 할 때, factored 방식을 사용하는 것이 더 유리하다.
- 추가적인 cross-check을 하는 것도 (factor + revise) 도움이 된다.
- CoVe를 붙인 Llama가 chatgpt나 기타 다른 모델보다 더 halluciantion을 적게 만든다.
- Verification 질문을 주관식으로 하는 것이, yes/no 문제로 하는 것보다 더 좋다
- Verification 질문을 짧게 하는 것이 더 좋다
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.