HydraLoRA, An Asymmetric LoRA Architecture for Efficient Fine-Tuning
논문 링크
배경
- LoRA와 같은 parameter efficient finetuning 방법론은 일반적으로 복잡한 데이터셋에 대해서 학습할 때, full finetuning에 비해서 성능이 좋지 못하다.
- 이런 문제를 해결하기 위한 지난 연구들의 노력에서, 두 가지를 확인할 수 있었다.
- 하나의 LoRA를 구성하기보다, 여러 개의 더 작은 LoRA head들을 구성해서 각각이 전문적인 역할을 하도록 만드는 것이 더 좋다.
- LoRA의 어떤 파라미터들은 공통의 내용을 학습하는데 반해서, 어떤 파라미터들은 특정한 task를 학습한다. (A: 공통의 내용, B: 전문적인 내용)
- 그래서 아래와 같은 asymmetric한 구조를 통해서 이를 효율적으로 구현했다.
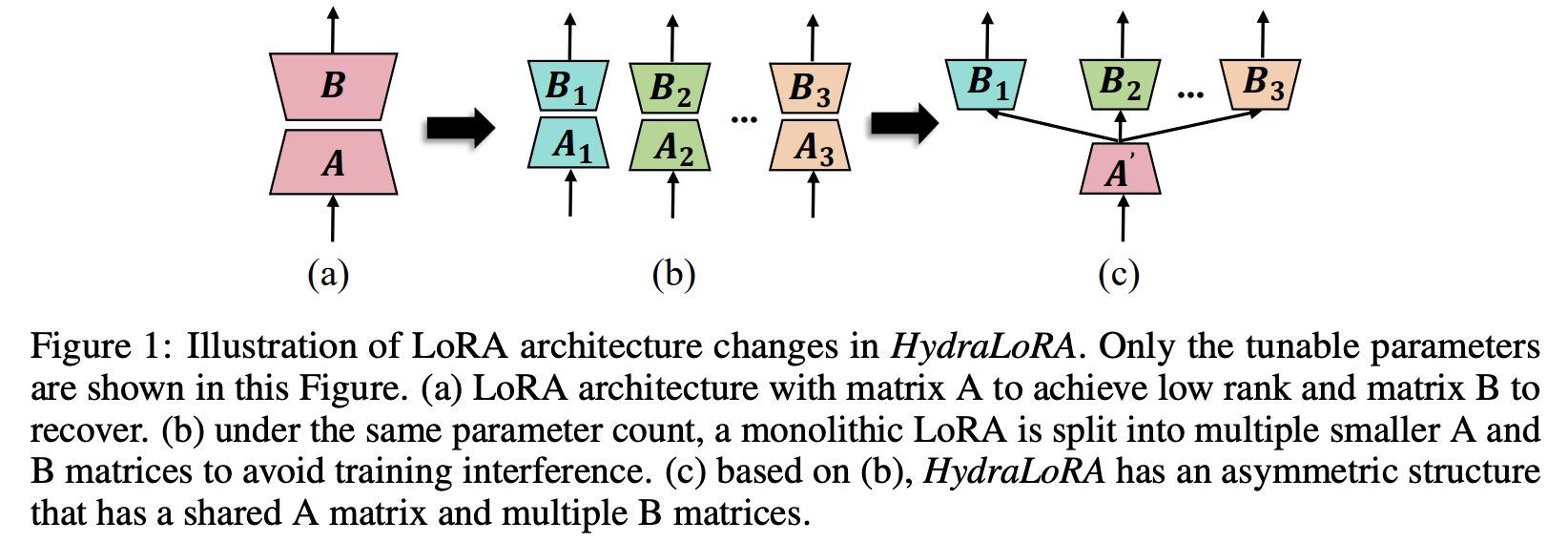
기존 방법의 문제
LoRA의 업데이트 방식은 아래와 같다. A/B는 W_0에 비해서 훨씬 작은 랭크를 가지고 있다. \(y\prime = y + \Delta{y} = W_0x + BAx\)
학습하는 파라미터 수를 줄이는 것은 학습의 효율을 증진시키지만, 그 성능은 떨어뜨린다. 특히나, fine-tuning용 데이터가 다양한 corpus를 가지고 있을수록, full finetuning에 비해서 성능이 크게 떨어진다.
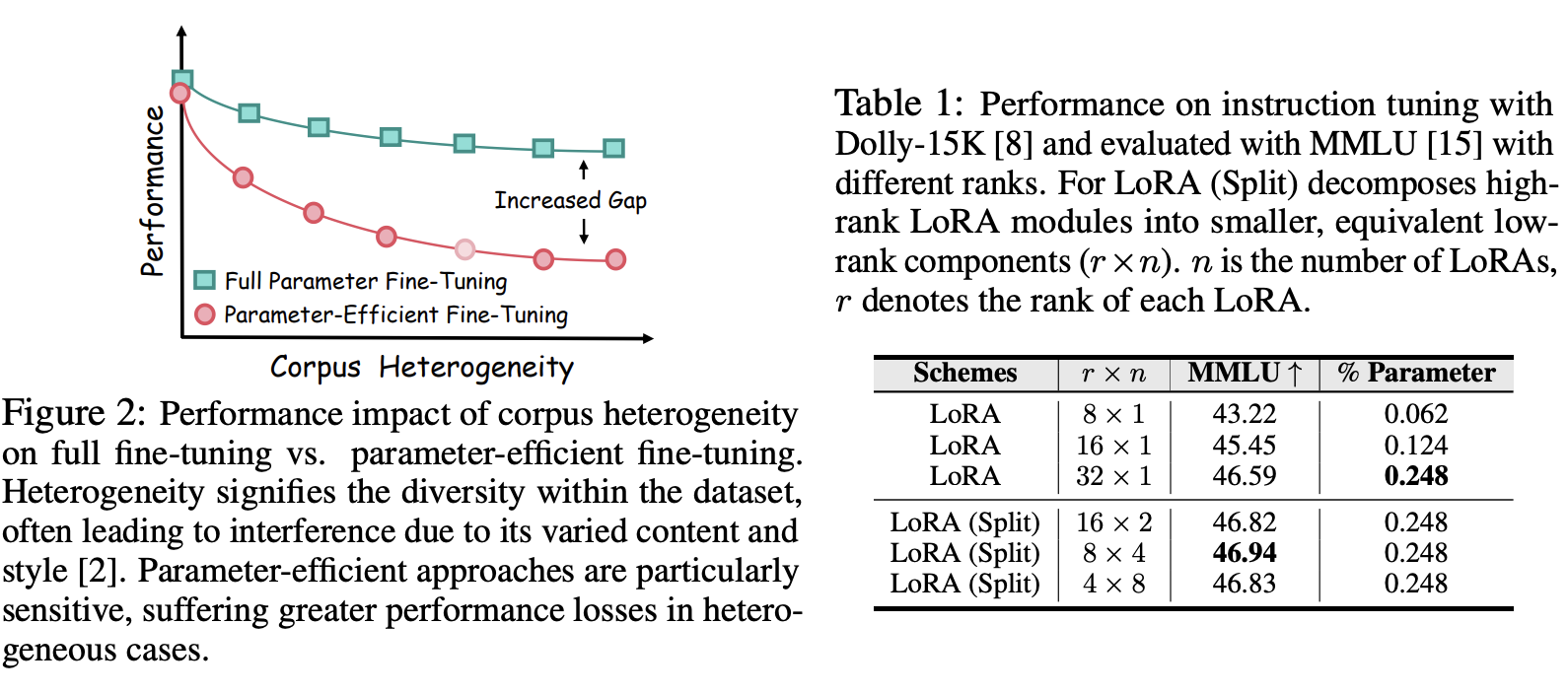
이런 실험들을 통해서, 아래의 두 현상을 관찰했다.
- Observation 1
- 같은 파라미터 수를 사용하더라도, 하나의 큰 LoRA를 사용하는 것보다, 더 작은 여러 LoRA를 사용하는 것이 더 효과적이다. (위의 table 1)
- Observation 2
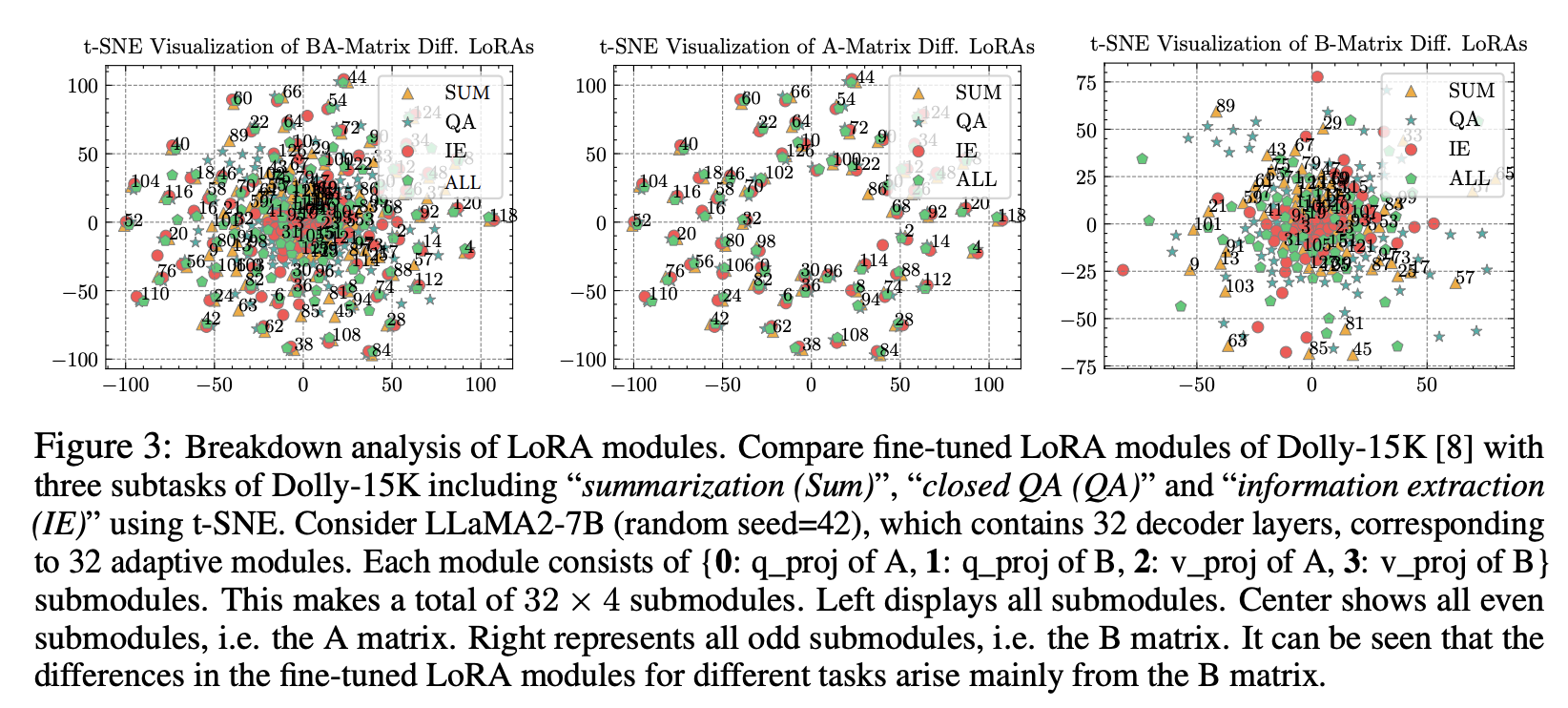
- 여러 LoRA 다양한 데이터에 대해서 각각 학습시켜도, matrix A는 수렴하고, B는 서로 다르게 학습되는 경향이 있다.
- Observation 1
HydraLoRA
Asymmetric LoRA는 아래와 같이 구성한다. \(W = W_0 + \Delta{W} = W_0 + \Sigma_{i=1}^N{w_i \cdot B_iA}\)
HydraLoRA의 workflow
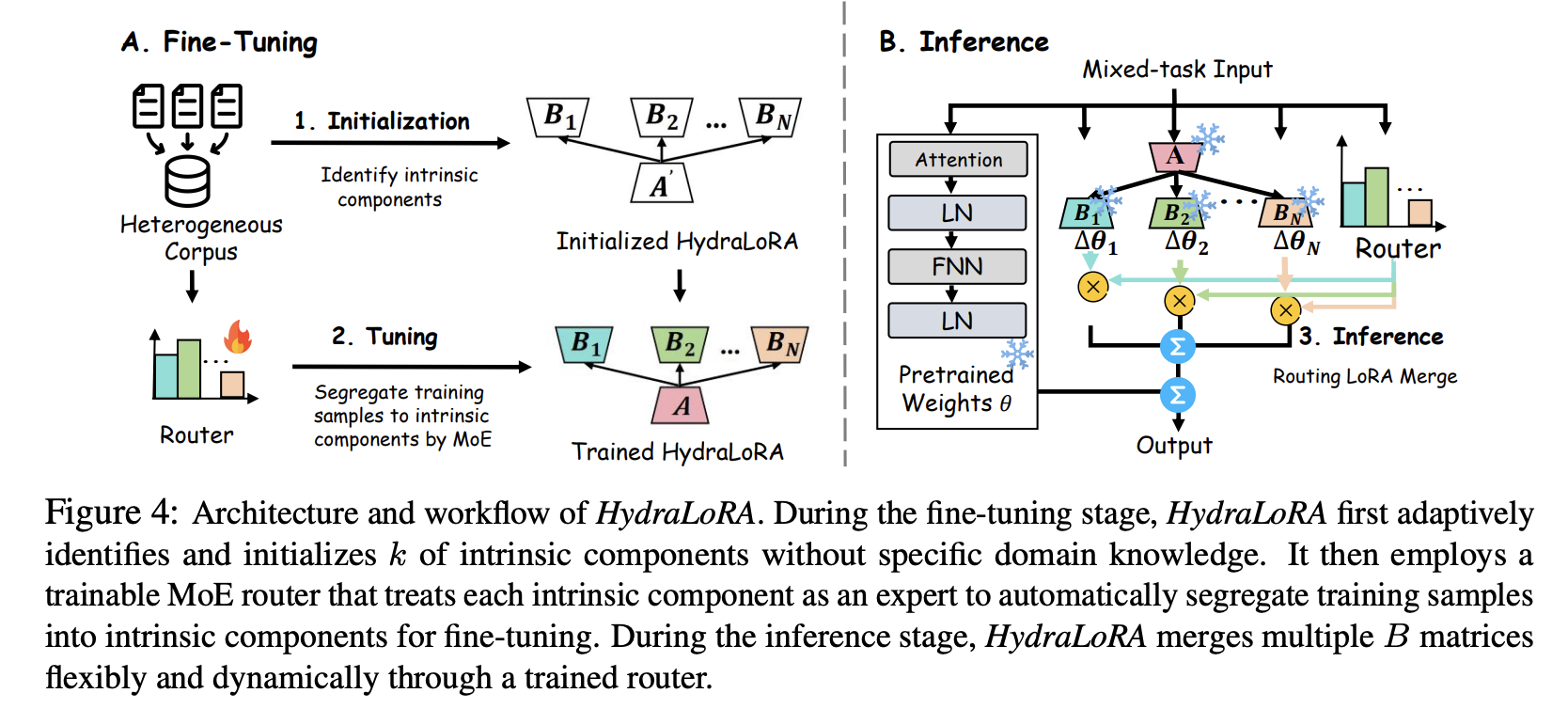
- Fine-Tuning
- Router와 각 LoRA를 같이 학습한다. 위 수식에서 w_i가 router의 값을 의미한다. \(y = W_0x + \Sigma_{i=1}^Nw_iE_iAx \newline w_i = softmax(W_g^Tx)\)
- Inference
- Router를 통해서 얻어진 softmax 값과, 각각 inference한 결과를 합쳐서 최종 inference를 한다.
- Fine-Tuning
실험
- 데이터 및 벤치마크
- Single domain
- General
- databricks-dolly로 학습하고, MMLU로 evaluate
- Medical
- chatdoctor로 학습하고, MMLU로 evaluate
- Law
- law-instruct와 us-terms로 학습하고 MMLU로 evaluate
- Math
- GSM8K를 학습/테스트로 나눠서 진행
- Code
- CodeAlpaca로 학습해서 HumanEval로 테스트
- General
- multi domain
- 학습은 Flanv2에서 샘플링한 데이터를 사용
- Big Bench Hard를 이용해서 evaluate
- Single domain
- 베이스라인
- single lora
- full fine tuning, p-tuning, prompt tuning, prefix tuning, IA3, AdaLora
- multi lora
- lorahub, loramoe
- single lora
- 분석
- RQ1: 같은 파라미터 숫자를 가정했을 때, 여러 개의 작은 LoRA를 쓰는 것이 하나의 LoRA를 쓰는 것보다 좋은가?
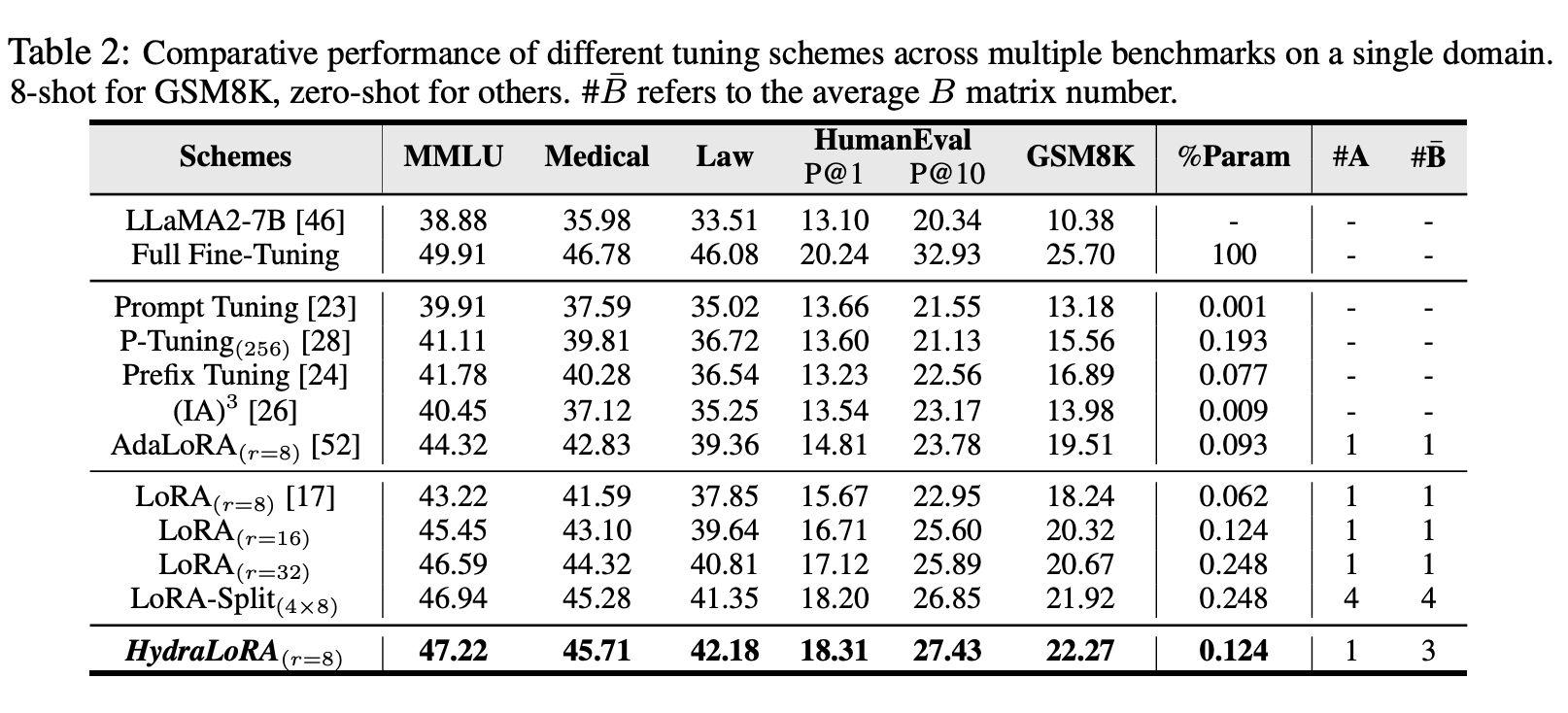
- 파라미터 개수가 비슷하다고 하면, lora-split이 lora보다 성능이 좋다.
- RQ2: 여러개의 LoRA를 서로 다른 데이터로 각각 학습시켰을 때, 각각의 B를 보다 효과적으로 학습시킬 수 있는가?
- 위의 그림에서 HydraLoRA가 더 좋은 것을 보면, Router를 포함해서 학습시키는 것이 그냥 깡으로 학습시키는 것보다 더 효과적으로 학습한다.
- 근데 직접 학습해보고 테스트 해보는게 젤 정확한 것 아닌가?ㅋㅋ
- 위의 그림에서 HydraLoRA가 더 좋은 것을 보면, Router를 포함해서 학습시키는 것이 그냥 깡으로 학습시키는 것보다 더 효과적으로 학습한다.
- RQ3: HydraLoRA가 merge 방법론에 비해서, 다양한 데이터를 학습하는 데 확장성과 강인한 측면에서 더 좋은가?
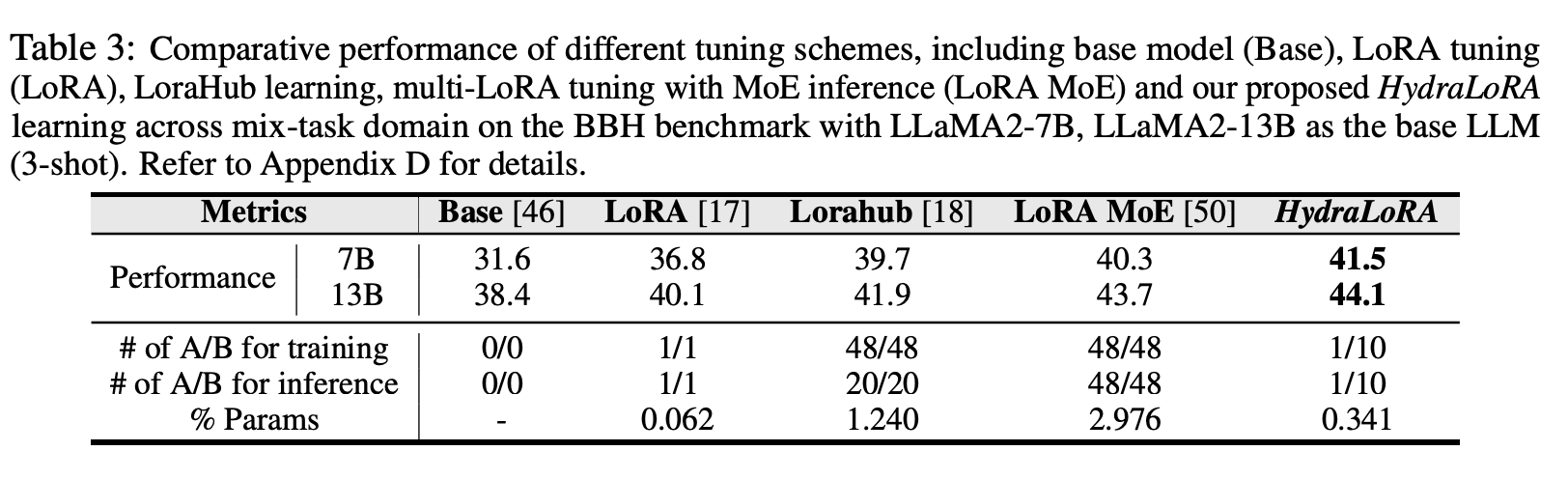
- RQ4: Hydra 구조가 학습할 때의 에너지와 추론 속도에 어느 정도 효율적인가?
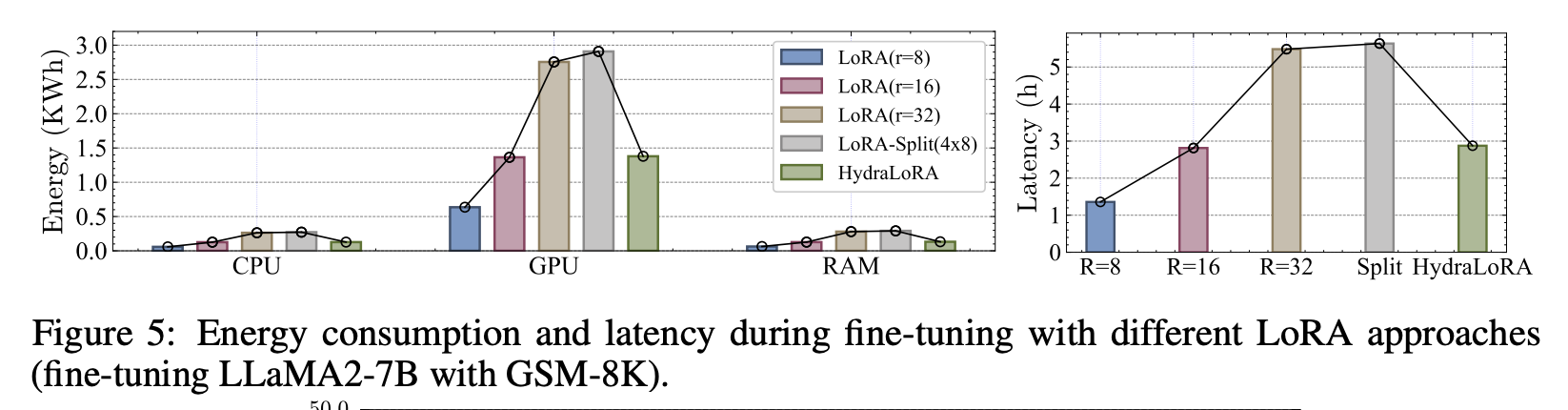
- 성능 대비로는 제일 효율적. 파라미터 사이즈로 치면 당연하지만, 동일한 파라미터 (r=16)과 동일
- RQ6: MoE구조와 gate가 fine-tuning 단계에서 어떤 영향을 주는가?
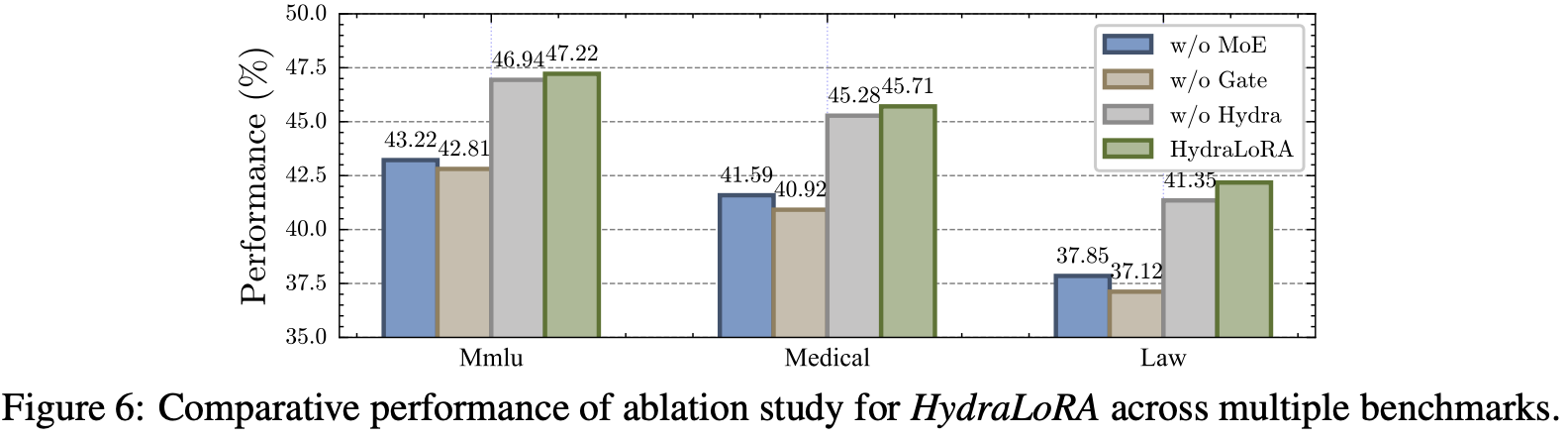
- 당연히 MoE와 Gate가 성능에 critical 하다. 근데 hydra 안하는 (A도 3개인) 것보다 hydra를 하는 것이 성능에서 더 좋다는 것이 신기함
- RQ7: LoRA head 숫자를 어떻게 골라야 하는가?
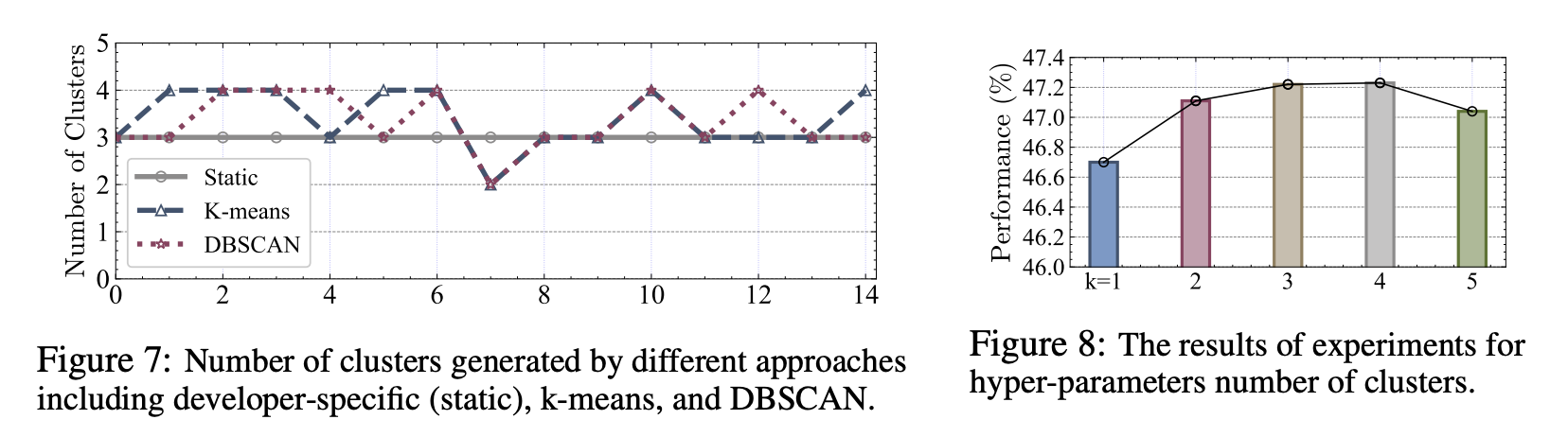
- 15개의 fold로 나눠서 분석해보면 2 ~ 4 정도가 나옴. 성능을 보면 3 혹은 4가 제일 좋다.
- 따라서, K-means와 같은 간단한 클러스터링으로 비교해서 head 숫자를 만드는 것이 제일 효율적이다.
- RQ1: 같은 파라미터 숫자를 가정했을 때, 여러 개의 작은 LoRA를 쓰는 것이 하나의 LoRA를 쓰는 것보다 좋은가?
결론
- 기존 PEFT의 단점 (여러 데이터셋의 경우에는 학습이 잘 안됨)을 줄이고, 학습 효율을 높인 HydraLoRA를 제안함
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.