GQA, Training Generalized Multi Query Transformer Models from Multi Head Checkpoints
논문 링크
배경
- 기존의 MHA (multi-head attention)의 속도를 개선하기 위해서 MQA (multi-query attention)이 나왔다. query만 multi-head로 하고, key와 value는 single head로 구성하는 방식.
- 속도는 빨라지지만, 다음의 두 가지 문제가 있음
- 실제적인 성능이 떨어짐
- 학습할 때 안정적이지 않음
- 이 논문에서는 MQA와 MHA의 중간 단계인 GQA (grouped-query attention)을 제안해서, 이 문제를 해결하고자 함.
- 제안하고자 하는 방법은 크게 두 가지인데,
- Uptraining
- 기존 MQA는 모델 구조를 바꿔서 새로 학습해야 했음. MHA로 학습이 잘 된 모델이 있었어도 마찬가지.
- MHA → MQA (GQA)로 빠르게 변환하는 방법을 제안
- GQA
- Uptraining
Uptraining
- MHA로 잘 학습된 모델이 있다고 했을 때, 이를 MQA로 바꾸기 위해서는, 모델 아키텍처를 바꾸고, 처음부터 다시 학습시켜야 한다.
- 이건 비효율적이고, 학습 결과도 안정적이지 못하게 된다. 이 문제를 해결하기 위해서, 새로운 Uptraining이라는 방법을 제안.
- Uptraining 방법
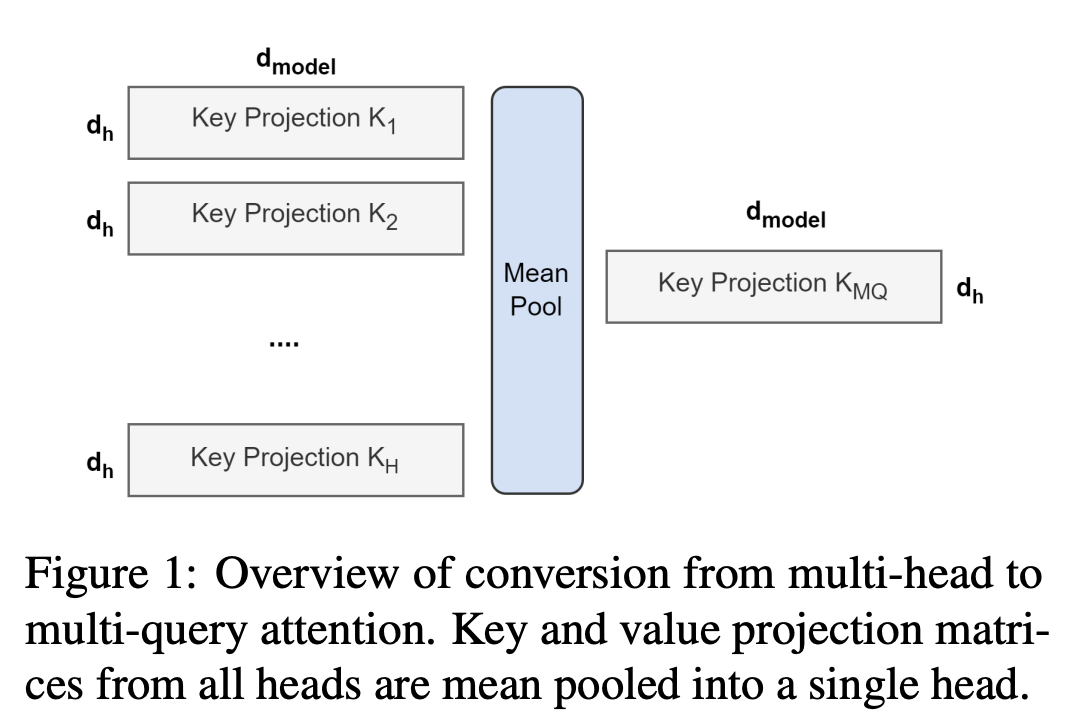
- 기존의 multi-head key/value를 mean pooling을 해서 하나의 single head로 바꾼다.
- 여러 헤드 중 하나만 고르거나, randomly initialize도 해봤지만, 이게 성능이 제일 좋았음
- 학습에서 필요했던 스텝보다 훨씬 적은 양만 추가로 학습시킨다.
- 기존의 multi-head key/value를 mean pooling을 해서 하나의 single head로 바꾼다.
Grouped-query Attention
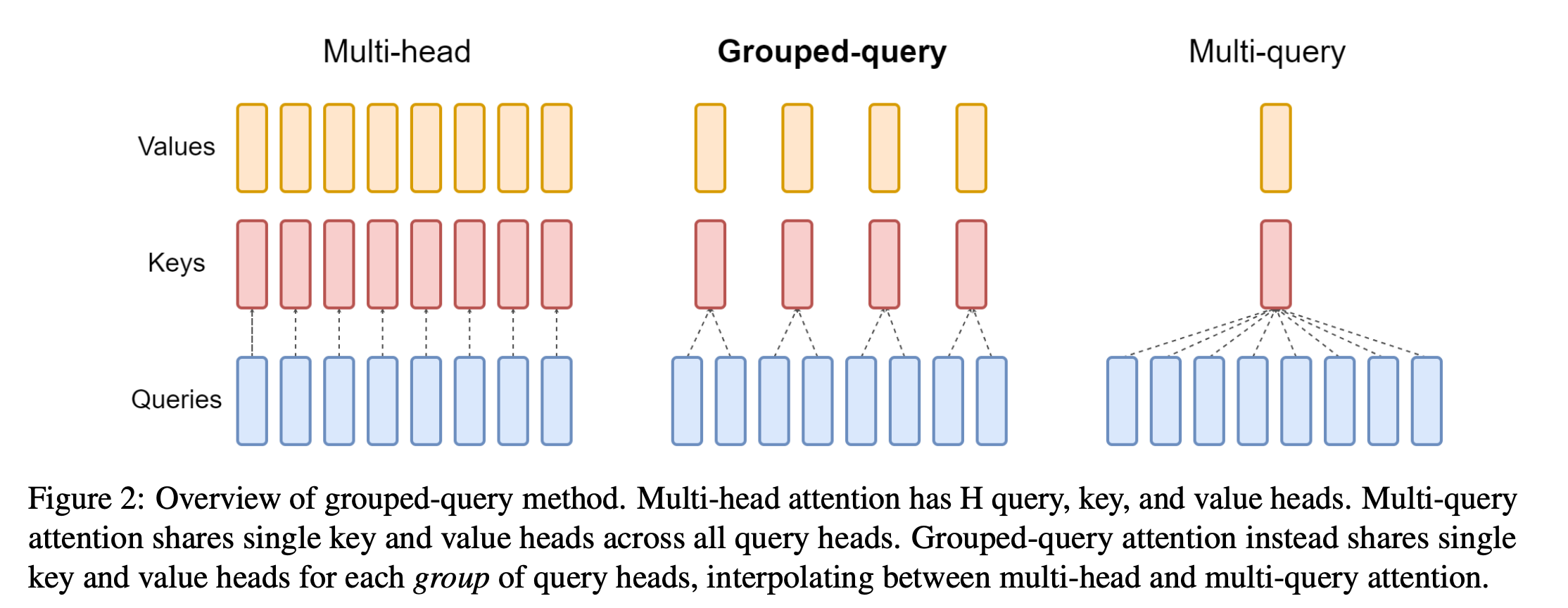
- MQA가 H개의 query head가 하나의 key에만 매핑되는 구조라면, 이걸 일반적으로 확장시켜서 k개의 query head가 하나의 key head에 매핑되도록 만든 구조.
- uptraining을 할 때는 마찬가지로, 매핑되는 k개를 mean pooling한 뒤에 학습시키는 방식을 사용함
Experiments
- Configuration
- 모델
- T5를 사용했다.
- Uptraining은 기존 대비 0.05 스텝만 학습시킴 (기존이 100스텝 학습시켰다면, 여기서는 5스텝만 학습)
- 데이터
- 요약 데이터, 번역 데이터 등을 사용함
- 장비
- TPU v4 칩을 사용함
- 모델
- 결과물
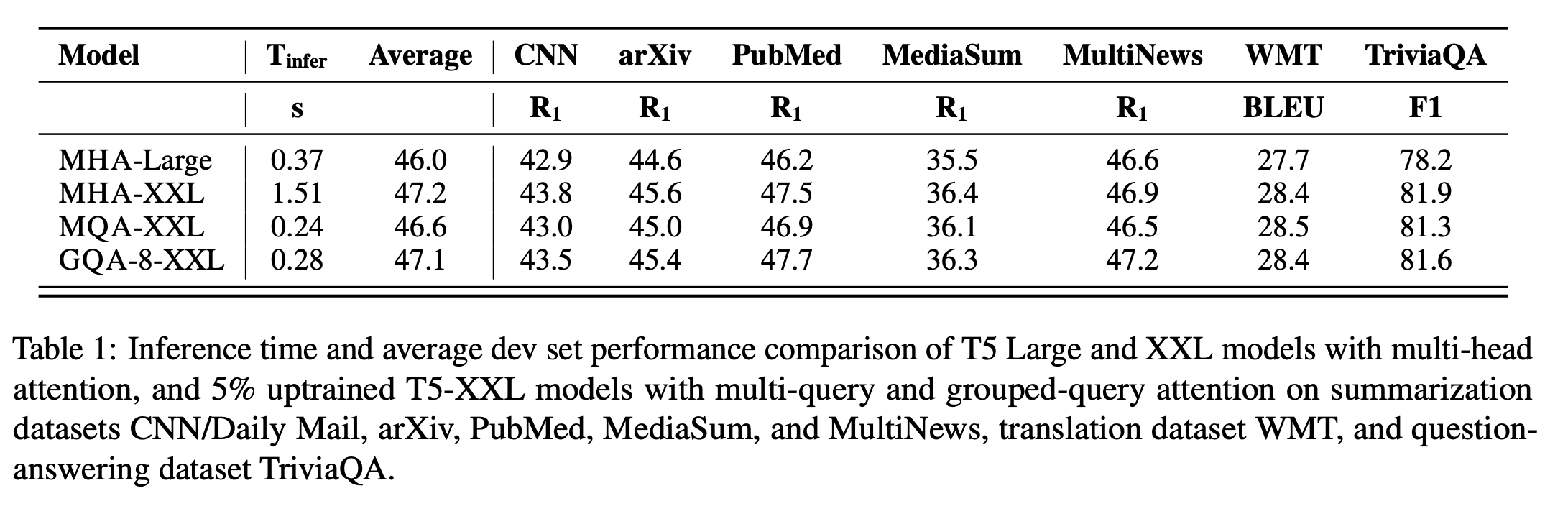
- 시간은 Large 모델과 비슷하게 걸리지만, 성능은 XXL 모델만큼 나옴 (GQA-XXL)
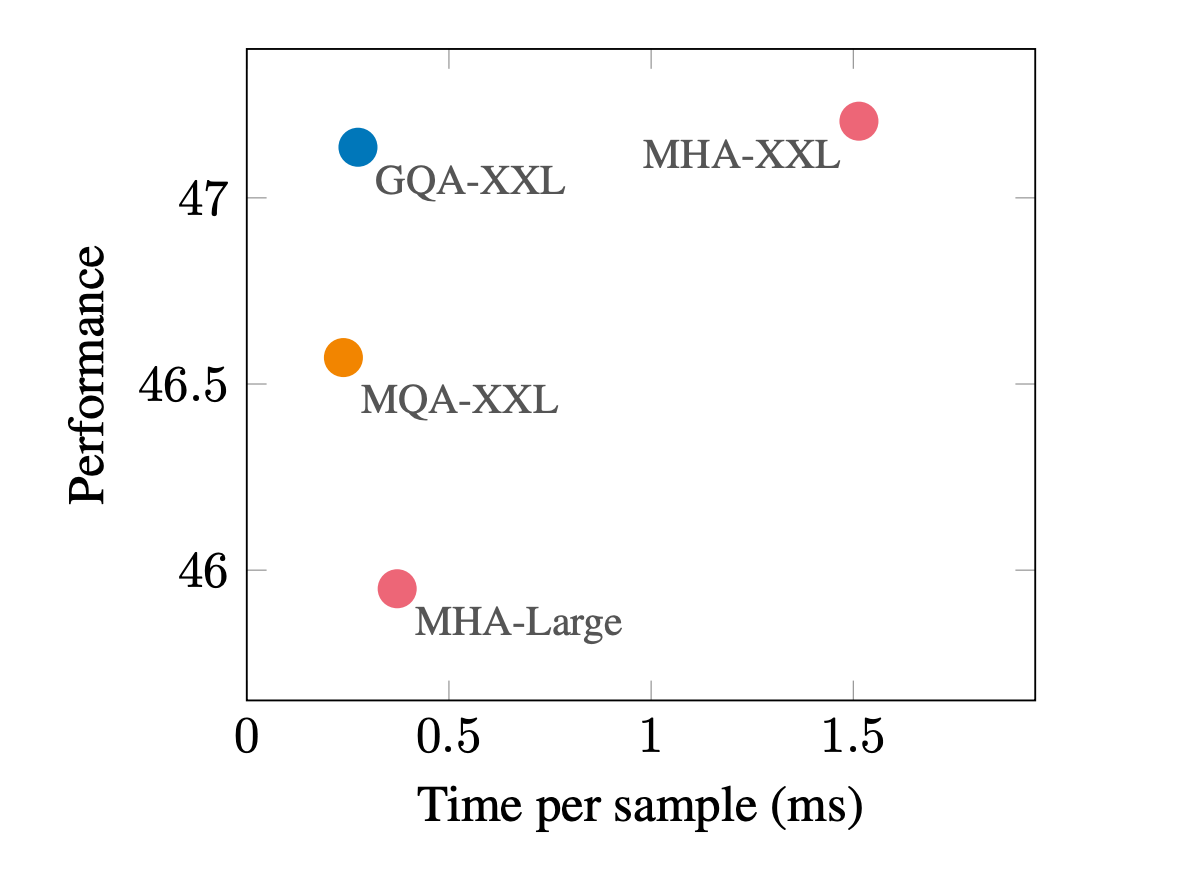
- 시간은 Large 모델과 비슷하게 걸리지만, 성능은 XXL 모델만큼 나옴 (GQA-XXL)
- Ablation study
- Uptrainig할 때 줄어든 head를 initialize하는 것 중 뭐가 가장 좋은가?

- 추가 학습은 어느정도 필요한가? (기존 대비 10%면 충분함)
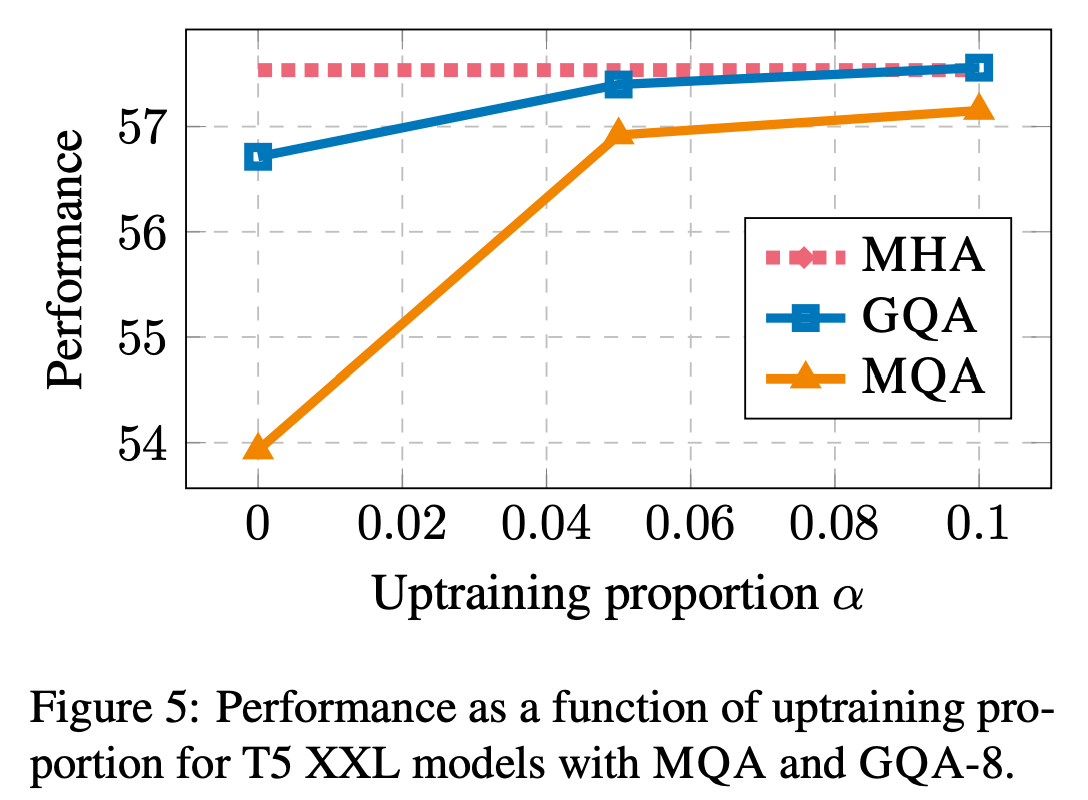
- Uptrainig할 때 줄어든 head를 initialize하는 것 중 뭐가 가장 좋은가?
결론
- GQA를 사용하면, memory bandwidth overhead (key, value를 로딩하는 데 걸리는 시간)을 줄여서 inference 속도를 개선할 수 있다.
- 또한, 처음부터 네트워크 구조 설계를 이렇게 하지 않았더라도, uptraining 방법을 통해서 쉽게 MHA → MQA/GQA로 변경이 가능하다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.