Foundational Autoraters, Taming Large Language Models for Better Automatic Evaluation
논문 링크
Overview
- LLM을 평가하는 방법은 보통 비싸거나 (전문가가 직접 evaluation), 성능이 떨어진다 (LLM을 이용하거나, crowd sourcing 등).
- 사람이 evaluation하는 방식은, 주관적이기도 하고, 변동성이 크기도 하며, 무엇보다 정확도를 높이기 위해서는 비용이 비싸다 (실제 가격의 측면에서도, 시간의 측면에서도)
- LLM을 이용하는 방식은 데이터 편향과 hallucination 문제가 있다.
- DeepMind는 공개된 데이터들을 이용해서, 일반적으로 evaluation을 잘 하는 모델을 학습시켰다.
- 지난 연구들에서 사용한 human evaluation 데이터를 약 530만건 정도 모았으며, 이를 잘 분류하고 평가해서 LLM을 이용하는 평가 방식의 단점을 보완했다.
- 이 모델들은 시중의 LLM (chatgpt4, claude3 등)보다 RewardBench에서 성능이 좋았으며, LLM-as-a-Judge 모델에 비해서 데이터 편향이 적었다.
Data (FLAMe Collection)
- 데이터 수집의 원칙
- 공개된 데이터셋
- 사람이 직접 레이블을 만든 데이터
- 다양한 Task Types
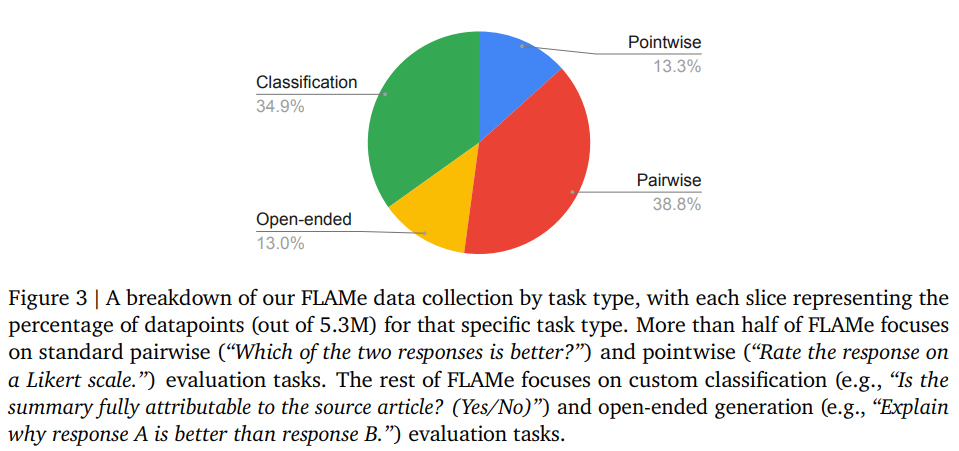
- Pairwise evaluation
- 일반적인 reward model 학습용 데이터. 같은 prompt에 대해서 두 개의 결과를 주고, 누가 더 좋은지 맞추는 데이터
- Pointwise evaluation
- 하나의 답변을 주고, 각각의 점수를 매기는 방식 (e.g. 별점)
- Classification
- 카테고리 분류 (e.g. 이 모델은 instruction을 잘 따랐는가? Yes/No)
- Open-ended Evaluation
- 자유롭게 답변하는 것
- Pairwise evaluation
- 다양한 LLM의 능력을 평가하는 데이터 셋 구축
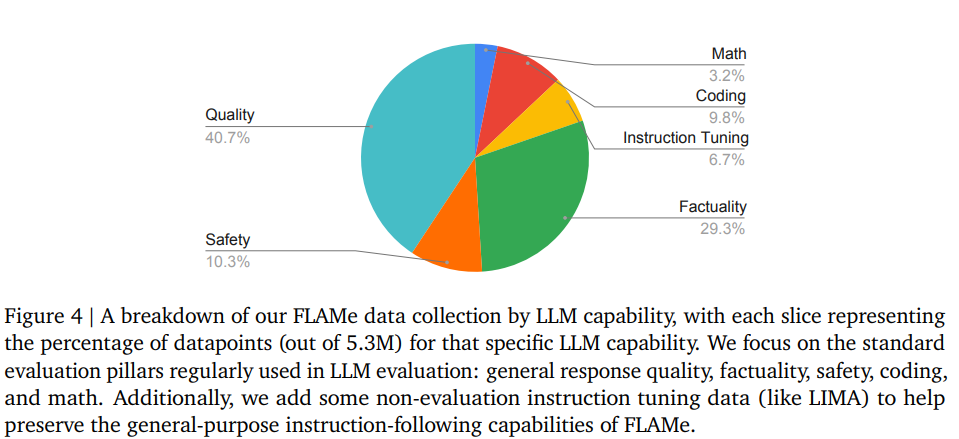
- 일반적인 답변 퀄리티
- helpfulness, coherence, fluency, creativity 등 다양한 모델의 성능을 평가
- Factuality/Attribution
- Mathematical Reasoning
- Coding
- Safety (Violence)
- Instruct Tuning
- 사람이 직접 작성한 답변으로 이루어진 데이터
- 일반적인 답변 퀄리티
- 학습 데이터 포맷의 일원화
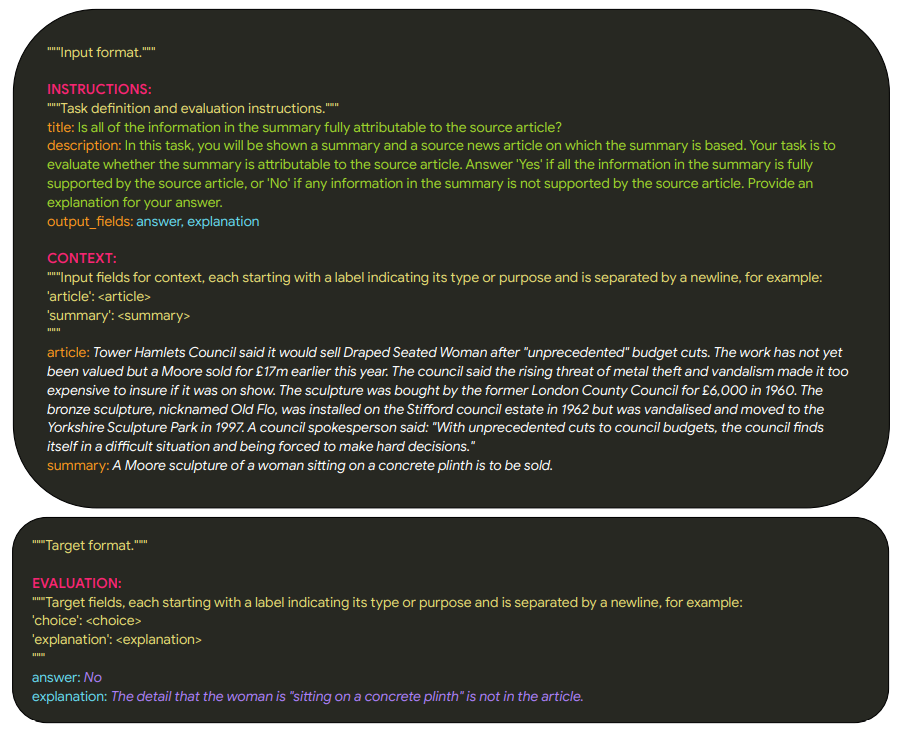
- 다양한 형태를 하나로 맞추기 위해서, text-to-text 형태의 데이터셋으로 구축함.
- 기존의 다른 형태로 된 데이터를 해치지 않기 위해서, 데이터 소유자와 이야기하고 다방면으로 고려해서 포맷을 변경.
- Instruction, Context, Evaluation의 세 개의 블록에 필요한 항목들을 넣도록 구성
- 다양한 형태를 하나로 맞추기 위해서, text-to-text 형태의 데이터셋으로 구축함.
모델
- FLAMe
- PaLM-2-24B를 베이스로 모델을 학습함 (full fine-tuning)
- 각 task 별로 skew되는 것을 방지하기 위해서, 최대 2^16의 데이터만 사용함
- 30K training step까지 학습
- FLAMe-RM
- reward model 전용으로, pairwise dataset만 추가로 학습을 더 함. 이 데이터는 앞에서 FLAMe에서도 학습한 데이터이므로, 50 step만 추가로 학습시킴
- FLAMe-Opt-RM
- 우리의 목적은 RewardBench에서 1등하는 것이 아니기 때문에, 보다 다양한 task를 잘 수행하는 모델이 필요함
- 중간 스텝까지 FLAMe을 학습한 뒤, 이 weight를 가지고 각 task 별로 짧게 (3000 스텝 이내) 학습시킴
- 그리고 각 task에 특화된 모델의 성능을 평가해서, 어떤 task의 데이터를 조금 더 높이고, 어떤 task의 데이터를 조금 더 줄여야 하는지 결정함
실험 결과
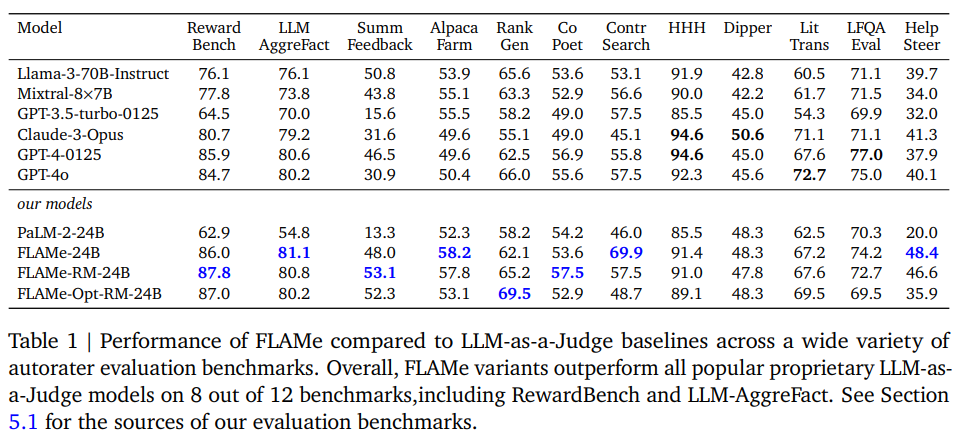
- RewardBench, LLM AggreFact등 공개된 leaderboard에서 가장 좋은 성능을 보였다.
- 특히, 보편적인 generative 모델과 비교했을 때 가장 좋았다 (classifier 모델들과 비교하면 성능이 약간 떨어지는 경향을 보임)
분석
- Bias Analysis
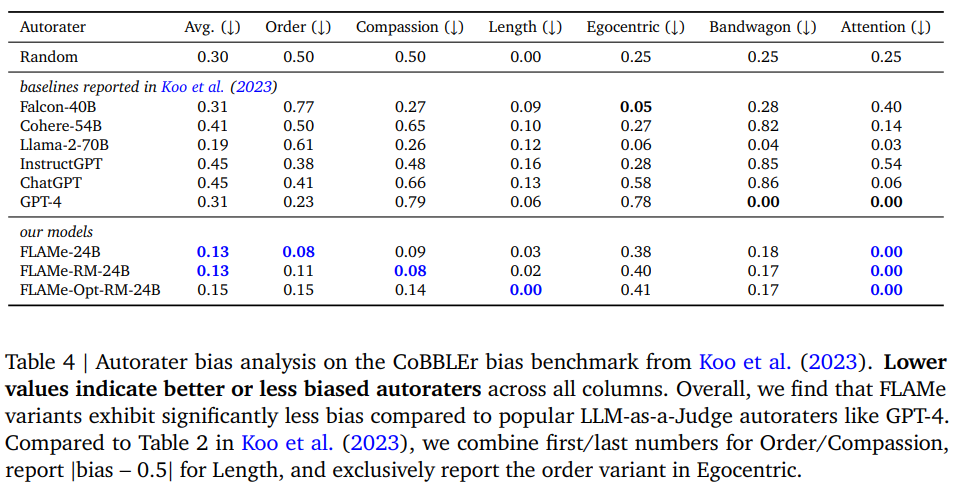
- CoBBLEr의 bias benchmark를 사용해서 테스트했고, 다른 벤치마크들보다 bias가 적었다. CoBBLEr는 아래와 같은 항목을 평가한다.
- Order
- A, B 중에 A를 좀 더 많이 선택하는 경향이 있는가?
- Compassion
- 고유명사를 쓰지 않고 지시대명사를 썼을 때 성능 변화가 있는가?
- Length
- 결과가 길어지거나 짧아지는 것에 결과 차이가 생기는가?
- Egocentric
- 자기자신이 생성한 결과에 조금 더 좋은 성능을 책정하는가?
- Bandwagon
90%의 사람들이 A를 선호해와 같은 문장에 따라 결과가 바뀌는가?
- Attention
- 전혀 무관한 문장이 들어감에 따라 결과가 바뀌는가?
- Order
- CoBBLEr의 bias benchmark를 사용해서 테스트했고, 다른 벤치마크들보다 bias가 적었다. CoBBLEr는 아래와 같은 항목을 평가한다.
- FLAMe을 re-ranking 알고리즘으로 활용하기
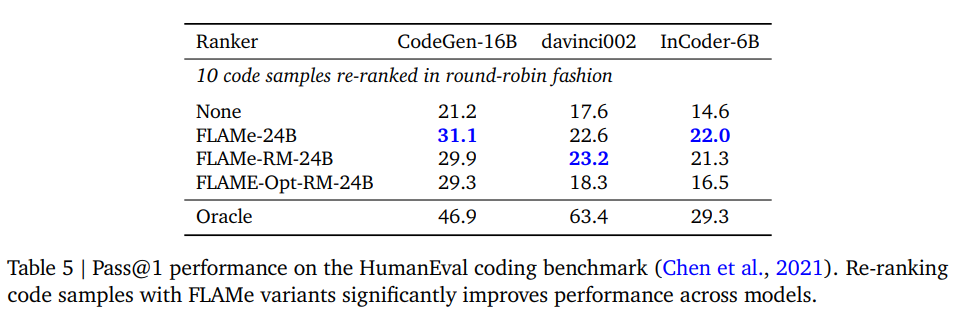
- Reranker로 FLAMe을 사용하면, 코딩 결과에서 성능이 크게 바뀐다.
결론
- 일반적인 목적의 Reward model을 학습할 때, 하나씩 specific하게 하는 것이 아니라, multitask로 학습해도 꽤 좋은 성능을 보인다.
- tail-patch 등을 통해서 bias를 제거하고, 이런 모델을 이용해서 re-ranking도 사용이 가능하다.
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.